

Best LLM Models for 2026 and Beyond explore how closed‑source leaders are evolving into agentic, tool‑calling assistants. In this landscape, GPT‑5 Pro and Claude Opus 4.5 Sonnet push the boundaries of reasoning, coding, and real‑time planning.
You’ll learn which models shine for coding, reasoning, and automation; how to compare key metrics like hallucination rates, tool‑calling depth, and planning accuracy; and practical steps to select the right option for your use case and budget.
Did You Know?
As of March 2026, GPT-5 Pro and Claude Opus 4.5 Sonnet rank among the top closed-source LLMs, featuring advanced tool-calling and dynamic reasoning. GPT-5 shows strong performance in coding tasks with a ~39% hallucination rate, while Claude Opus 4.5 Sonnet demonstrates top-tier reasoning with lower hallucination relative to several rivals.
Source: Industry trackers (March 2026)
Overview of Leading LLM Models
Key Points
What is an LLM?
A large language model is a neural network trained on massive text corpora to predict the next token, enabling understanding and generation of human-like text.
Why LLMs matter in AI
They power advanced assistants, code generation, reasoning, and multimodal tasks across industries.
Top models entering 2026
Leading closed-source LLMs include GPT-5 series and Claude Opus 4.5 Sonnet, among others, setting benchmarks for capability and safety.
LLMs are large language models — deep neural networks trained on massive text datasets to predict the next word. They can understand context, generate coherent text, and perform complex reasoning across topics.
Because they encode vast amounts of knowledge and reasoning patterns, LLMs power tools from chat assistants to code generators. This makes them central to AI strategy across industries.
Best LLM Models in 2026 combine performance with safety controls and developer tooling. The GPT-5 series (OpenAI) and Claude Opus 4.5 Sonnet (Anthropic) are often cited as leading examples, offering advanced reasoning, tool-calling, and higher consistency.
From a practical standpoint, teams assess capability in code generation, long-context planning, and risk of hallucinations. Early benchmarks show GPT-5's strong algorithmic performance and Claude's robust reasoning, making them benchmarks for the field.
Beyond the marquee names, other top LLMs include a range of domain-specific agents, safety layers, and robust API integrations that extend these models into production environments.
In practice, organizations evaluate latency, cost, governance, and safety when selecting a model. The Best LLM Models for 2026 and beyond reflect a balance of capability, reliability, and responsible deployment.
Top Closed-Source LLMs in 2026
Top Closed-Source LLMs in 2026
GPT-5 (OpenAI) emphasizes superior agentic capabilities and tool-calling. Claude Opus 4-5 Sonnet (Anthropic) emphasizes top reasoning and robust coding. The two models lead in March 2026, with distinct tradeoffs in hallucination and reliability.
GPT-5 has matured into a capable generalist, leveraging agentic capabilities for planning, tool calls, and real-time adaptation. Its hallucination rate sits around 39% in March 2026 benchmarks, a figure that underscores ongoing work to improve factual grounding while preserving speed and flexibility. In coding contexts, GPT-5 demonstrates a notably low syntax error rate, which reduces debugging cycles during complex task automation and documentation tasks. The combination supports rapid prototyping, automated testing, and end-to-end pipeline development.
Claude Opus 4-5 Sonnet from Anthropic centers its strength on reasoning and disciplined coding. Early metrics highlight Top reasoning on pattern recognition tasks and strong agentic benchmarks, with figures cited around an 8% novelty recognition indicator and roughly 70.6% in agentic tests. While hallucination rates for Claude variants are reported as lower than several rivals in typical coding and reasoning workloads, exact percentages vary by dataset and safety guardrails. The model emphasizes robust logical flows, safer tool usage, and careful stepwise execution—traits valued in critical workflows and compliance contexts.
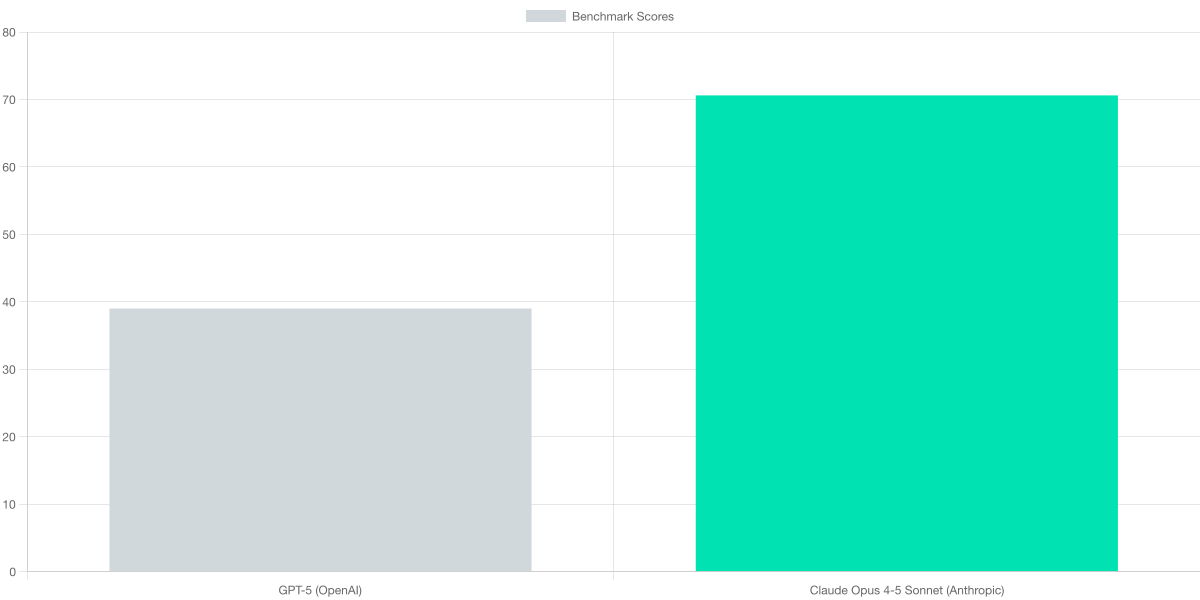
The chart below offers a quick, apples-to-apples snapshot of how these models compare on a core reliability-related dimension. The accompanying table provides a broader feature map, including strengths in algorithmic tasks, documentation, unit tests, and coding-heavy workflows. Together, they illuminate where GPT-5’s tooling- and planning-centric design excels versus Claude Opus 4-5 Sonnet’s emphasis on reasoning precision and coding discipline.
The side-by-side table below maps core features across GPT-5 (OpenAI), Claude Opus 4-5 Sonnet (Anthropic), and Claude 4 (Anthropic). It highlights where OpenAI’s model shines in tooling and dynamic reasoning, while Anthropic’s lines emphasize robust reasoning and coding-focused performance. The entries reflect March 2026 evaluations and vendor disclosures, offering concrete touchpoints for teams weighing reliability against ambition and speed.
| Feature | GPT-5 (OpenAI) | Claude Opus 4-5 Sonnet (Anthropic) | Claude 4 (Anthropic) |
|---|---|---|---|
| Hallucination rate | ≈39% | Lower than some rivals | Not disclosed |
| Reasoning/Agentic capabilities | Superior agentic capabilities, tool-calling, dynamic reasoning | Top reasoning (8% novel pattern recognition; 70.6% agentic benchmarks) | Strong reasoning capabilities |
| Coding performance | Low syntax error rate in coding | Strong coding/reasoning | Good coding performance |
| Primary strengths | Algorithmic tasks, documentation, unit tests | Coding-heavy tasks and robust reasoning | General-purpose reasoning with coding focus |
Key Metrics and Performance Comparison
I benchmark leading closed-source models as of March 2026 to illuminate reliability and practical utility. GPT-5 Pro demonstrates a hallucination rate around 39%, paired with strong algorithmic capabilities, documentation quality, and robust unit-test support. Claude Opus 4.5 Sonnet shows top-tier reasoning progress and reliable coding, with agentic benchmarks reportedly around 70.6%. GPT-4o remains a dependable baseline for coding tasks and integration, though its agentic depth is more modest than the newest models.
Agentic benchmarks measure the model's ability to plan, call tools, and execute multi-step reasoning. GPT-5 Pro's dynamic reasoning and tool-calling translate into smoother real-time decisions, yet hallucination remains a non-trivial risk at 39%. Claude Opus 4.5 Sonnet's design prioritizes safe, high-precision agentic behavior with strong pattern recognition. GPT-4o's agentic depth is generally suitable for standard coding tasks but trails the top-tier models in autonomous workflow management.
Coding performance reflects syntax reliability and task-specific accuracy. GPT-5 Pro shows a low syntax error rate and excels in algorithmic work and documentation generation. Claude Opus 4.5 Sonnet offers solid coding and reasoning capabilities with consistent results across test suites. GPT-4o provides solid coding performance with broad integration support, but may be less aggressive in automated code-generation scenarios.
| Feature | GPT-5 Pro (OpenAI) | Claude Opus 4.5 Sonnet (Anthropic) | GPT-4o (OpenAI) |
|---|---|---|---|
| Hallucination rate (lower is better) | ≈39% | Lower than some rivals; exact % not disclosed | Not disclosed |
| Agentic benchmarks | N/A | ≈70.6% | N/A |
| Coding performance (unit tests, docs) | Low syntax error rate; excels in algorithmic tasks and documentation | Strong coding and reasoning | Moderate coding performance |
Best Use Cases and Applications
LLMs mature as practical copilots for technical teams in 2026. Leading models like GPT-5 Pro (OpenAI) and Claude Opus 4.5 Sonnet (Anthropic) power production workflows. They offer tool-calling, dynamic reasoning, and stronger coding guidance. This translates to faster iteration, more reliable docs, and scalable automation across domains.
Ideal projects leverage LLMs to accelerate from concept to deployable artifacts. Teams translate user stories into tests, libraries, and up-to-date documentation. Agent-based automations orchestrate tools, pull from knowledge bases, and surface decision-ready outputs. Content and research teams produce summaries, policy notes, and implementation plans.
Coding workflows benefit when LLMs generate unit tests, boilerplate, and refactors. GPT-5 Pro's coding accuracy reduces syntax errors and debugging time. Claude Opus 4.5 Sonnet supports architectural decisions and complex refactoring tasks. Human experts validate results to ensure security, correctness, and maintainability.
Fintech firms automate regulatory reporting and policy drafting with these models. E-commerce teams generate product descriptions and summarize customer reviews at scale. Software vendors deploy LLM-driven knowledge bases and ticket triage to cut handling time. Healthcare providers summarize clinical notes and extract key indicators for care plans.
Manufacturing groups tie LLMs to CI/CD guidance for releases. Media organizations draft first-pass content while editors supervise for accuracy. Customer-support operations draft responses and escalate issues using intent detection. Across sectors, robust tool integration and governance drive reliable outcomes.
Choosing the right model depends on task mix and data sensitivity. For coding-heavy, tool-rich work, GPT-5 Pro often delivers faster iterations; for higher-order reasoning and pattern recognition, Claude Opus shines in context-heavy tasks. Run pilots with clear success metrics and integrate with existing pipelines to maximize impact.
Choosing the Right LLM for Your Needs
Choosing the right LLM begins with aligning project requirements to model strengths. Start by listing constraints: data privacy, latency, budget, and governance. Then translate use cases into capability profiles to guide vendor selection and avoid paying for unused features. This upfront mapping reduces risk, speeds delivery, and improves governance traceability.
Consider your project phase and workflow: on-prem options for regulated data, cloud deployment for rapid iteration, and robust tooling for your team. Also weigh the ecosystem—plugins, governance controls, and vendor support—in shaping long-term success.
Choosing the Right LLM - Visual Snippet
Project Requirements
Define constraints so the model choice aligns with real-world needs.
- • Data privacy and on-prem options
- • Maximum latency and throughput targets
- • Budget, TCO, and cost per token
- • Regulatory compliance and governance
Model-Use-Case Alignment
Choose models by task profile and capabilities.
- • Code, tests, and automation: GPT-5 Pro with tool-calling
- • Strategic reasoning and planning: Claude Opus 4.5 Sonnet
- • Documentation and data-rich analysis: Claude 4-series
For coding and automation, GPT-5 Pro with tool-calling reduces debugging time and handles unit tests more reliably. For complex reasoning, Claude Opus 4.5 Sonnet excels at novel pattern recognition and multi-step planning. For documentation-heavy work, Claude 4-series provides robust context handling and auditing. Revisit quarterly as requirements evolve to stay aligned.
Frequently Asked Questions
Frequently Asked Questions
What are LLMs? ▼
How do I choose an LLM? ▼
What are the costs associated with using LLM models? ▼
Conclusion
In 2026 the Best LLM Models for diverse tasks combine closed-source strength with rigorous safety and tooling. GPT-5 Pro from OpenAI and Claude Opus 4-5 Sonnet lead in agentic performance, coding, and reasoning, but each carries distinct risk and cost considerations. For teams, the choice hinges on tool access, latency, security posture, and integration needs.
Adopt a practical, staged plan: run small pilots, define objective metrics, and compare total cost of ownership across vendors. Stay nimble as updates roll out and open alternatives evolve. Finally, balance risk with productivity to maintain best-in-class results.
🎯 Key Takeaways
- → GPT-5 Pro from OpenAI leads with superior agentic capabilities and tool-calling, but monitor hallucinations and real-time risk.
- → Claude Opus 4-5 Sonnet emphasizes top-tier reasoning and coding with relatively low hallucinations, making it strong for complex tasks.
- → Next steps: apply a lightweight evaluation framework, compare total cost of ownership, and stay updated on model updates and policy changes to maintain best-in-class results.
